Information is the new gold. Just like hidden reserves fueled the California Gold Rush of 1848, vast troves of data hold the potential to unlock immense value for businesses. Take Netflix, for example. They leveraged advanced data analytics and saved USD 1 billion annually through improved customer retention and personalized recommendations.
Unlike the prospectors of old, businesses today need more than pickaxes and shovels to unearth these riches. They need a specialized team – data scientists and data engineers – to transform raw information into actionable insights. What’s the difference between a data engineer and a data scientist?
Imagine you're a chef with a pantry overflowing with exotic ingredients. A data scientist is a visionary recipe developer. They analyze those ingredients to discover hidden flavor combinations and craft mouthwatering dishes. They can't simply toss everything into a pot and hope for the best.
That's where the data engineer comes in — they're the skilled culinary expert who builds the kitchen, ensures the freshest ingredients are available, and meticulously measures each addition to create the perfect dish.
And there is no “data scientist vs data engineer”. A successful business needs both. But what exactly sets them apart, and why do you need both in your organization? That's the secret sauce we'll be revealing in this article.
Close the gap between data and decision-making with data management to drive innovation up to 75%
Demystifying the roles: Data scientist vs. Data engineer
This part explores the difference between a data engineer and a data scientist. Let’s break down their unique areas of expertise.
Data scientist: Looking for insights
It may sound weird, yet similar enough: a data scientist is akin to a detective. Their primary focus is on extracting valuable insights and knowledge from data to inform strategic business decisions. They are always on the lookout for valuable informational gems in the sea of facts.
Extracts knowledge and insights from data
Data scientists scrutinize large datasets to uncover patterns, trends, and dependencies. They crystalize innovation-promising insights from the found scope of information. Thinking back to our Gold Rush metaphor, a data scientist’s job is similar to leaching gold out of a ton of sand.
Hand in hand with statistics, ML, and programming
Armed with a strong foundation in statistics and machine learning, data scientists create sophisticated algorithms and models. They are proficient in programming languages like Python, R, and SQL, which they use to manipulate data and build predictive models.
Builds models to predict future trends
Today’s business environment proves the famous saying: We must run as fast as we can, just to stay in place. It isn’t enough to satisfy current customers’ needs; modern successful companies can predict future needs.
And Data Scientists develop such predictive models that help businesses anticipate future trends and customer behaviors. For example, a retail company might use these models to forecast sales trends, optimize inventory, or personalize marketing campaigns.
Additionally, a big part of Data Scientist’s responsibilities lies in model training. They take their massive data collection and break it down into three parts — one for training, one for testing, and another for validation. They then crank up the volume on the training mix, letting the algorithm groove to it and spit out predictions, kind of like predicting the next big thing. Depending on the assets and what they're trying to achieve, they might go for a more structured order with supervised learning or let the algorithm “freestyle” with unsupervised learning.
Data scientist needs to understand each ingredient's properties (data points) and how they interact (statistical relationships) to create a masterpiece (predictive model) that delights the customers (business stakeholders).
Learn more about distinctions between data analytics and data science
Data engineer: Structures and translates insights into reality
A data engineer, on the other hand, is the architect behind the scenes. They design, build, and maintain the infrastructure necessary for data access, storage, and processing.
Designs, builds and maintains the data infrastructure
Data engineers are responsible for constructing the data pipelines and storage solutions that handle vast amounts of data. They ensure that data flows smoothly from its source to the data scientists who will analyze it.
Knows databases, data pipelines, and cloud technologies inside out
Data engineers have deep knowledge of databases (like SQL and NoSQL), data pipeline frameworks (like Apache Kafka and Apache Airflow), and cloud platforms (like AWS, Google Cloud, and Azure). They use these tools to build scalable and robust data architectures.
Ensures data quality, security, and accessibility
Data engineers prioritize maintaining high data quality. They implement data validation, cleaning, and transformation processes to ensure that the data is accurate and reliable. Additionally, they enforce data security measures to protect sensitive information and ensure that the data is easily accessible for analysis.
Data engineer is the architect who designs and constructs a state-of-the-art kitchen for the chef (as in the previous example about the data scientist). They lay out the kitchen (data infrastructure), ensure all the appliances work perfectly (data quality and pipelines), and make sure the kitchen is secure and accessible (data security and accessibility).
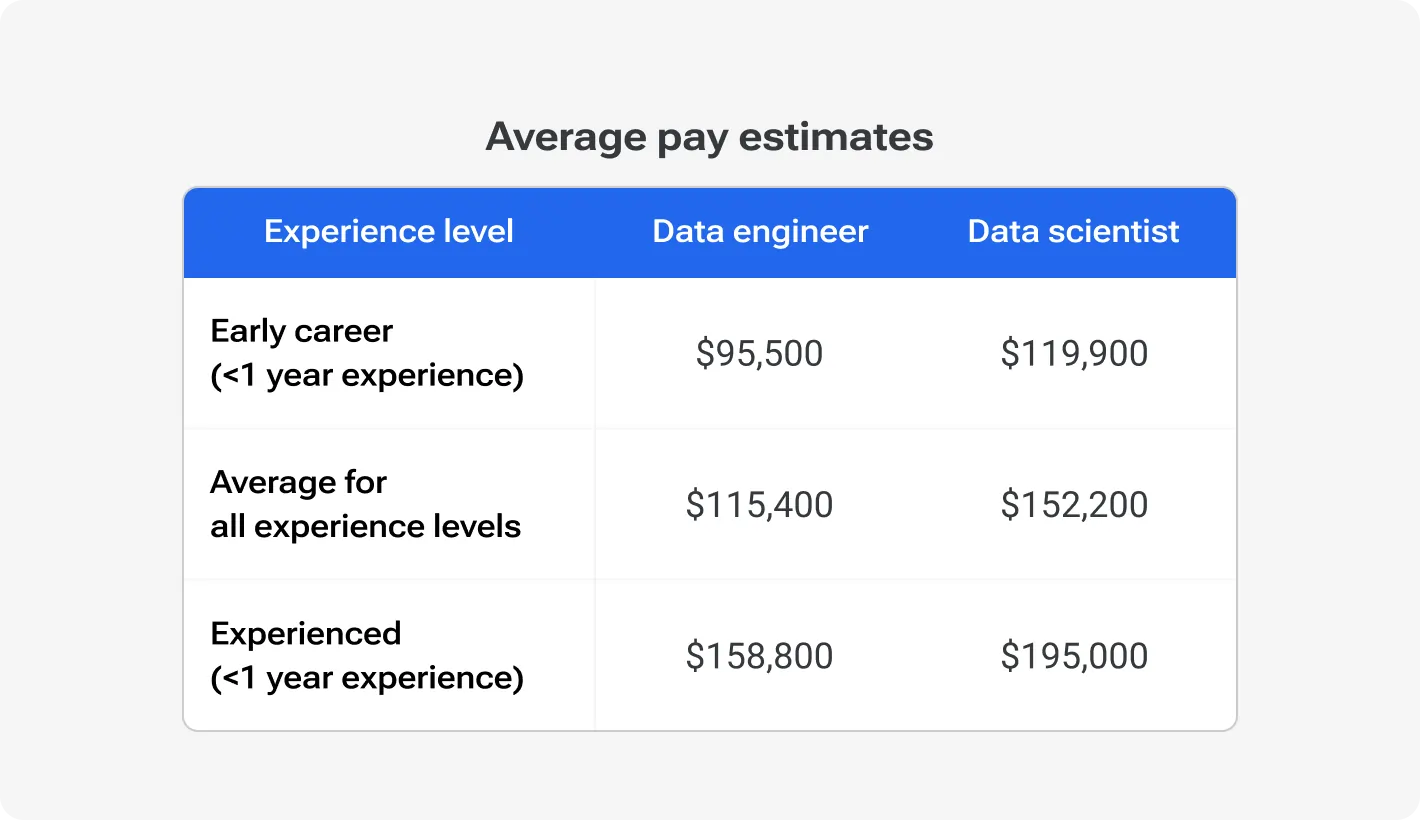
Last but not least, the difference also lies in the material aspect. Compare the average salaries of Data Engineers and Data Scientists.
Unveiling the divide: Key differences between the roles
It seems that the difference between data science and data engineering lies in “the depth” of diving into numbers. However, this is too superficial an understanding. While both roles are integral to data-driven success, they serve distinct functions within the data ecosystem. And every business owner who has aspirations to win the lion’s share of the market should know the nuances. Let’s compare key aspects that distinguish these two roles.
Data Scientists typically have a background in mathematics, statistics, or computer science, while Data Engineers might have a background in computer science, information technology, or software engineering.
Additionally, Data Scientists often work in close collaboration with business analysts to understand specific business needs, while data engineers collaborate with system administrators and DevOps teams to ensure smooth data pipeline integration with existing IT infrastructure.
And one more time about the outputs — they vary significantly. Data Scientists produce predictive models, insights, and data-driven recommendations that inform business strategies. Data Engineers, in turn, deliver robust data pipelines, ETL (Extract, Transform, Load) processes, and reliable data storage solutions that enable seamless data access and analysis.
Data science and Data engineering: Employ both and nurture the dream data team
Data science and data engineering are two sides of the same coin. When these roles work together, they complement each other and drive significant business value.
Imagine a Formula One race team. The driver (lightning-fast reflexes and strategic decision-making) is a data scientist. They possess the skills and knowledge to steer the car (data) towards victory (valuable insights for business profit).
But behind the wheel sits another critical player — the pit crew, a data engineering team in our case. Their meticulous work in ensuring the car is well-maintained, fueled (clean data), and strategically pit-stopped (efficient data pipelines) is what allows the driver to push the car to its limits and achieve peak performance.
Just like in Formula One, data scientists and data engineers play distinct yet interdependent roles in creating a holistic data-driven approach within a company.
Creating a holistic data-driven approach
As we mentioned, these two critical professionals must work in tandem to create a seamless data-driven approach. Another analogy for clarity: there is a city where engineers build the infrastructure – roads, bridges, and utilities – while urban planners design how the city will function and grow.
So here, Data Engineers lay the groundwork by creating robust data pipelines while Data Scientists analyze and interpret this data to provide actionable insights.
Tip: Set up regular meetings between data scientists and data engineers to ensure alignment on goals and methodologies. Syncs are as important as planning.
Data engineering: The foundation for data science
Dirty data leads to distorted insights. Data Engineers are responsible for clean, well-structured, and easily accessible data. They build pipelines and databases that capture, store, and process data from various sources. This fundamental work prepares fertile ground for Data Scientists.
For example, a retail company might use data engineering to integrate sales data from multiple channels into a centralized data warehouse.
Tip: Implement automated data validation checks within your data pipelines to maintain data quality. This way, your Data Scientists will always have access to accurate and reliable data.
Learn more about automation for data engineering teams
Collaboration molds: Churn prediction
Let’s say a telecommunications company wants to reduce customer churn. Data Engineers gather and clean data from various sources, including customer interactions, billing records, and service usage logs. By the way, there are customer data platforms (CDP) for this reason. Then, Data Engineers create a data warehouse where this information is stored.
Data Scientists easily take it over. Using machine learning algorithms, they analyze the data to identify patterns and signals that predict churn. They build models that can forecast which customers are likely to leave and why. The insights gained from these models allow the company to take proactive measures, such as targeted marketing campaigns or personalized offers, to retain at-risk customers.
Tip: Use joint project management tools like Jira or Trello to track the progress of collaborative projects. This keeps everyone on the same page and facilitates seamless collaboration.
Challenges of siloed teams and benefits of collaboration
Any silos inevitably lead to misaligned goals, duplicated efforts, and lost opportunities. If Data Engineers and Data Scientists work in isolation, the engineers might not understand the specific data requirements of the scientists, which may result in suboptimal data pipelines. Conversely, scientists might spend excessive time cleaning data instead of analyzing it.
Such a scenario often happens in the healthcare industry, where data is often scattered across different departments and systems. This fragmentation hinders comprehensive analysis and slows down critical decision-making processes.
In contrast, fostering a collaborative data culture can yield significant benefits. When the team works closely together, they can streamline processes, enhance data quality, and accelerate time-to-insight. Obviously, this leads to business progress (read profit).
Tip: Create interdisciplinary teams that include both Data Engineers and Data Scientists. Create an environment for them to effortlessly collaborate and share knowledge without any barriers.
Learn top strategies for improving your data engineering workflows
Building a successful data team
To build a successful data team, pick these strategies up:
Encourage cross-training: Allow data engineers to learn about data science and vice versa. This cross-training fosters mutual respect and understanding, which enhances collaboration.
Joint project ownership: Assign both data engineers and data scientists to the same projects. This joint ownership ensures that both roles are invested in the project's success.
Open communication channels: Choose communication channels that suit your goals. Microsoft Teams, Slack, whatever. Don’t shy away from weekly stand-ups or touchpoints to facilitate ongoing dialogue between teams.
Unified goals: Belonging is one of the most in-demand feelings and needs. Employ it. Create an atmosphere where every team member feels like a part of a big, meaningful machine. Align team goals with business objectives to ensure that everyone is working towards the same outcomes.
To sum it up
Data engineers build the robust infrastructure needed for data storage and processing, while Data Scientists analyze this data to derive actionable insights. This collaboration allows the creation of a business success.
What is the difference between a data engineer and a data scientist? The first are the architects, building the foundation for data access and analysis. The second are visionary analysts who extract knowledge and insights from data.
Having both roles in your company ensures that data flows smoothly from raw collection to insightful analysis, enabling better decision-making, optimized operations, and strategic growth. The teamwork between data scientists and data engineers forms the backbone of any successful data strategy.
Fast-paced business world forces entrepreneurs to leverage the power of data fully. So, make sure to invest in building strong, interdisciplinary data teams that include both data scientists and data engineers. This investment will pave the way for innovative solutions and a competitive edge in today's data-driven world.
Don't fight for tech talent, get access to data engineers today