When it comes to data engineering workflows, the challenges grow alongside data volume and complexity. Data engineers often find themselves stuck in daily firefights, addressing pipeline errors, performance bottlenecks, and manual tweaks. This cycle stifles innovation and strategic thinking.
So, how can complex workflows be optimized to enhance productivity and speed up insights? The answer lies in workflow optimization. Regular improvements in efficiency and reliability can reduce errors and speed up data processing, providing valuable insights faster and gaining a competitive edge.
In this article, we will explore eight key strategies for optimizing data engineering workflows. We’ll focus our attention on automation and data monitoring, some core improvements and security issues, agile methodologies and disruptive technologies. We’ll also explore trending data engineering best practices that can help you become a top leader in your industry.
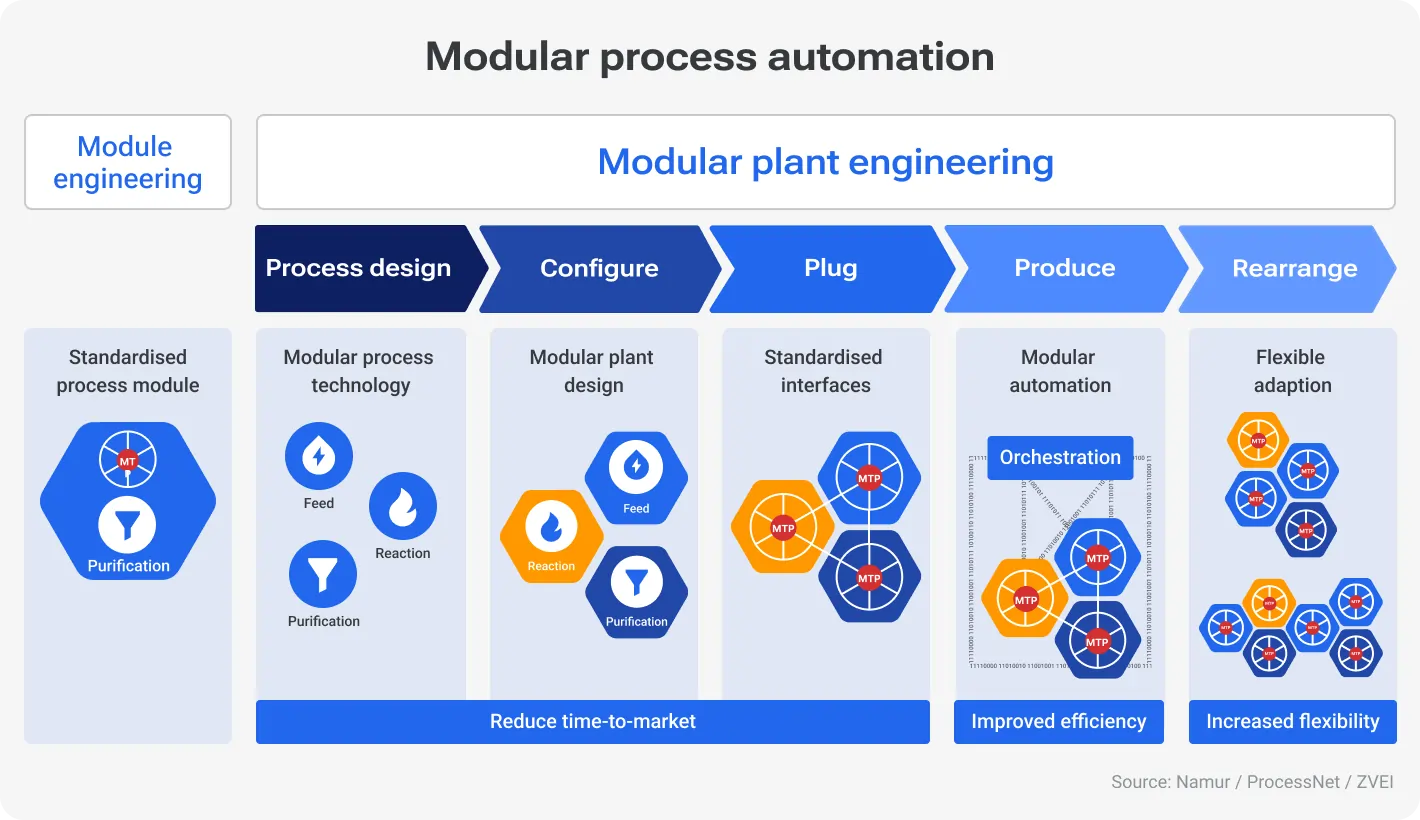
Start with basics: Automation and modular design
So, your first and most obvious decision would be to automate and simplify the workflow. It’ll allow you to stay competitive and create efficient, scalable, and maintainable data pipelines. Let’s explore automation first.
Automation is the backbone of modern data engineering. It allows teams to handle large volumes of data with greater efficiency and accuracy. Automating repetitive tasks such as data extraction, transformation, and loading (ETL) can save time and reduce human error.
An IDC study forecasts that by 2026, up to 75% of data engineering workflows will be at least partially automated.
Benefits of data pipeline automation:
Higher efficiency: focus on more strategic and complex issues, rather than manual data processing.
Better accuracy: minimize the risk of human error, ensuring that data is processed consistently every time.
Scalability: scale and adjust to manage larger datasets without significant manual intervention.
Of course, you’ll need specific tools to manage this task. While the choice depends on your demands and data volumes, there are some common tools that most data engineers prefer to use. For example, Airflow allows you to schedule and monitor the workflows. It is almost perfect for the automation of complex data pipelines. As popular scripting languages, Python and R, are widely used to automate data extraction, transformation, and load tasks. Libraries such as Pandas in Python simplify data manipulation and processing. Moreover, specialized tools like Talend, Informatica, and AWS Glue provide comprehensive platforms for automating ETL processes. If you need some more information on what is best for your particular tasks don’t hesitate to have advice from professionals.
Close the gap between data and decision-making with data management to drive innovation up to 75%
Now, let’s talk closely about simplifying the workflow. What can help you here is a modular design. Basically, you break down complex workflows into smaller, reusable components or modules. This approach helps you to scale and adapt to changing requirements much easier.
With modular design, you get:
Maintainability: smaller, self-contained modules are easier to test, debug, and maintain.
Reusability: modules can be reused across different workflows and projects which saves a lot of time.
Scalability: you can scale individual components of the workflow as needed.
Although it may seem that this is one of the most effective practices, remember that before implementing it, you need to clearly understand your main goals, select services that can be divided into modules, and use modern technologies for this. Here is how automation and modular design helped big company streamline their data engineering workflow.
AirBnB transit to modular design
Airbnb handles massive amounts of data daily. Their data team needed a robust and scalable solution to manage data ingestion, processing, and analysis efficiently. They apply Airflow to programmatically author, schedule, and monitor data pipelines. Starting back in 2018, they now use a modular approach when designing ETL pipelines. Each pipeline is divided into distinct modules for data extraction, transformation, and loading. These modules are developed, tested, and maintained independently. It allows for the enhancement of the overall maintainability of the system.
Keep it clear: Data monitoring and performance optimization
Your other field of concern is pipeline maintenance. It should be always efficient and reliable, otherwise, you’ll get false insights or, even worse, lose time and won’t get anything at all. Here you can adopt proactive data monitoring and performance optimization as part of a data engineering strategy. It’ll help you to ensure that data systems run smoothly, accurately, and efficiently.
As it clears from its name, monitoring means observing data pipelines to detect and meet issues before they become problems. It allows you to take care of data integrity and timely data delivery.
Thanks to proactive data monitoring you can:
Detect errors in the early stages and avoid system failures and troubles.
Find data corruption, missing data, and other quality issues and correct them promptly.
Identify performance bottlenecks and inefficiencies in data pipelines.
Ensure data processing complies with regulatory standards.
You can use various tools and methods to track data quality and identify performance bottlenecks. The main techniques include data quality monitoring and the search for weak points in performance.
Monitoring data quality
In short, monitoring data quality and lineage involves tracking the accuracy and completeness of data as it moves through the pipeline. Thanks to this, you can guarantee the visibility of the origin and transformations of data, their transparency, and traceability.
Handy tools:
Great Expectations to define, test, and validate data expectations. It is quite useful as it allows to set data quality rules and generate detailed reports on data validation results.
Apache Atlas for data governance and metadata management as it helps with data lineage tracking.
Data Catalogs, like Alation and Collibra, also provide a centralized platform for managing metadata and ensuring data quality.
Identifying performance bottlenecks
Identifying performance bottlenecks involves finding and dealing with inefficiencies in data processing pipelines. It is usually focused on data transformations and processing time.
Handy tools:
A combination of Prometheus and Grafana. While Prometheus collects metrics from various systems, Grafana visualizes and displays these metrics in customizable dashboards. Together, they provide real-time monitoring and alerting for performance issues.
For data pipelines running on AWS, CloudWatch provides monitoring and logging capabilities.
Setting up alerts
And of course, when we speak about proactive monitoring, we mean you have to be alerted about any dangerous situation before it occurs in the system. It’ll let you respond quickly to issues that may disrupt data flow.
Handy tools:
PagerDuty is widely used to get real-time alerts and for efficient on-call management.
Datadog and Prometheus, which can be easily integrated with your business communication system, will send alerts directly to Slack channels.
Airflow offers custom alerting rules based on specific conditions.
As you can see proactive monitoring and data performance optimization are critical components of effective data engineer workflow. You can easily implement them as a data engineering strategy to maintain scalable data systems and support the organization's operational and strategic goals.
Make it a weapon: Data-driven workflow improvement
To have data and not use it or use it incorrectly is like stopping halfway to victory. What we mean is that while working on data engineering process optimization you should pay special attention to... data, as it allows you to identify areas for improvement. Based on it data engineers can enhance their processes and ensure that data systems operate at peak performance. It is what we call data-driven workflow improvement.
Your task here is pretty simple: systematically collect and examine workflow data to analyze it. It’ll help to pinpoint inefficiencies, detect bottlenecks, and implement changes that lead to better overall performance. Why is it among the important data engineering steps?
Data-driven approaches rely on objective metrics rather than intuition, which helps to make more informed and effective decisions.
Regular analysis of workflow data allows for continuous improvement to keep workflows efficient and up-to-date.
Identifying and eliminating inefficiencies helps optimize the use of resources, reduce costs, and improve productivity.
Tracking and analyzing key performance indicators (KPI) provides clear performance benchmarks, and promotes accountability and transparency across the team.
By the way, about the proper KPI. It is a pretty common practice but you should always remember to implement only those that are efficient and impactful for you. This is not the case where the more the better. Be wise in choosing major indicators to get more value, not more bureaucracy and analysis.
Here is a short list for your convenience:
Workflow efficiency to measure how effectively data pipelines execute tasks.
Job success rate to find out the percentage of data processing jobs that are completed successfully without errors.
Resource utilization to identify CPU, memory, and storage usage during data processing.
Data quality to assess the accuracy, completeness, and consistency of data.
Error rates to be aware of the frequency of data errors or anomalies detected in the pipeline.
Processing times to evaluate the speed and efficiency of data processing tasks.
When it comes to a large amount of data and its processing, not only the speed and selectivity of information are important but also its presentation. Here visualization tools will come to your aid. Data visualization tools help transform raw data into literally visual representations, making it easier to identify trends, patterns, and areas for improvement.
With a proper visualization tool, you are capable of:
Creating dashboards that display key KPIs and performance metrics: it is a comprehensive view of data workflow health, which highlights critical areas;
Identifying trends and patterns in workflow performance to reveal recurring issues, seasonal variations, and long-term improvements or declines;
Detecting anomalies in workflow performance, like sudden spikes in error rates or processing times;
Benchmarking and comparison to assess whether workflows are improving over time and how they stack up against data engineering best practices.
Make data your best friend and weapon in the fight against errors and bottlenecks in your pipelines. This will help you gain a competitive advantage and constantly update your processes.
Protect data workflows: Security and version control
As data pipelines handle sensitive and valuable information, it is crucial to implement robust security measures to protect this data from potential breaches. This is where you should solve a whole bunch of issues: secure data, maintain its integrity, and comply with regulatory requirements. You have to ensure that data is protected throughout its lifecycle: from extraction to processing, storage, and analysis. Your main concern is unauthorized access that can be gained through gaps in your safety protocols.
Build your information security system on three main principles:
Confidentiality: Data accessible only to authorized users;
Integrity: Data protected from alteration;
Availability: Data accessible to authorized users when needed.
Although a lot of companies are now focused on leveraging blockchain and its capabilities, there are also some other efficient practices you should consider. To provide maximum data safety you can apply multiple layers of protection.
Reliable security measures:
Encryption algorithms: Implement AES (Advanced Encryption Standard) for stored data and TLS (Transport Layer Security) for data in transit.
Access control: Use multi-factor authentication (MFA), role-based access control (RBAC) and regularly review access permissions.
Version control: Use Git and DVC (Data Version Control), ensuring a detailed history and quick rollback capabilities.
Last but not least, do not try to incorporate all security practices at once to get the most efficient system. Be selective and meticulous, and keep in mind your current demands and the need to scale in the future. Use the budget rationally here but don't try to cut it.
Stay in-touch: Communication and knowledge sharing
One of the reasons for the failure of some data projects is poor communication within the data team and with other employees of the company who are also involved in the project. So why don't you make it a point of optimization and growth?
Clear communication and knowledge sharing within the team help ensure that everyone is aligned, informed, and capable of contributing their best work. You just have to stay on the same page to be productive and efficient. So you can avoid duplication of efforts and minimize misunderstandings that can lead to errors or rework. With a properly built communication system, you’ll be able to create a transparent and understandable data engineering roadmap and encourage the exchange of ideas and solutions. To foster a collaborative environment, data engineering teams can adopt several strategies.
Documentation of workflows
Complete documentation is essential to maintain clarity and consistency across the team. This guarantees that everyone has access to the same information and can follow established procedures.
Here are some core elements of efficient workflow documentation:
Diagrams as a visual representation of data channels and processes to help team members understand the overall structure and flow of data;
Standard operating procedures (SOPs) or detailed instructions for performing specific tasks to ensure consistency and reduce training time for new team members;
Best practices or guidelines for coding standards, data processing, and other important aspects of data development for better uniformity and quality.
You can also utilize different tools for documentation. From usual Google Docs and standard applications to something more specific, like Confluence by Atlassian, which allows teams to create, share, and manage documentation in a centralized location. Or Notion, an all-in-one workspace that supports documentation, project management, and knowledge sharing.
Learn more about automation for data engineering teams
Regular team meetings
Of course, this is not a new concert and currently, many specialists complain that the meetings are becoming too much, that the time spent at the meetings could be spent on the performance of a certain task. However, it is one of the most effective ways to synchronize the team and by using it wisely and with balance you can achieve the best results.
Regular meetings provide a platform for team members to discuss progress, share insights, and address challenges collectively.
These meetings can take various forms:
Stand-up meetings for brief updates on tasks to highlight any blockers, and outline plans for the day.
Sprint reviews at the end of each sprint (in agile methodologies) to discuss what was accomplished, showcase new features, and gather feedback.
Retrospectives to reflect on what went well, what didn’t, and how the team can improve in future sprints.
Knowledge-sharing sessions, where team members can present on specific topics, share new tools or techniques, and discuss industry trends.
Choose the form that best suits your needs and teams, and try to optimize the number of meetings toward quality.
Standardized coding practices
Long-term work with code requires care and the use of best practices. It also includes regular code reviews to maintain its purity, transparency, and integrity. You can implement coding standards and conduct regular code reviews to maintain code quality and ensure that all team members follow the same guidelines.
There are two options for you here:
-
Establish and enforce coding standards and style guides to safeguard consistency and readability. Take in mind naming conventions, code structure, and documentation practices.
-
Implement a structured code review process where team members review each other’s code. This is how you can identify potential issues early, improve code quality, and facilitate knowledge sharing.
You can enforce coding standards automatically with ESLint for JavaScript, Pylint for Python, and Prettier for code formatting. Or you can use pull requests in GitHub (or similar platforms like GitLab or Bitbucket) for code reviews.
Cooperation within the team makes it possible to achieve great success. Together the team members become stronger as they get the necessary support and awareness.
Never stop moving forward: Stay up-to-date with trends
An unexpected trap that data engineers fall into is to stay where they are because it works. It is very tempting because familiar things feel like something stable and time-tested. Nevertheless, as time actually shows, only constant updating and improvements allow you to achieve the best results and goals after all.
Keeping pace with the latest developments in data engineering opens up new opportunities for innovation as new tools and techniques can lead to more efficient and effective data solutions. Moreover, staying current with industry trends helps maintain a competitive edge, while emerging technologies often offer more streamlined and scalable solutions. So, let's take a closer look at some trends in data engineering workflow optimization.
Cloud-based data engineering platforms
Cloud-based platforms have revolutionized data engineering already, as they are perfect solutions for data storage, processing, and analytics. A report by Flexera reveals that 94% of enterprises have embraced cloud technologies and proceed to improve their performance with them.
With cloud-based platforms, you can:
Easily scale resources up or down based on demand, and ensure optimal performance without over-provisioning;
Reduce upfront costs and optimize resource usage;
Access to a wide range of services and tools to build customized data solutions;
Enhance collaboration by allowing team members to access and work on data from anywhere.
There are several of the most widespread and reliable platforms now: Amazon Web Services (AWS), Google Cloud Platform (GCP), and Microsoft Azure. They offer suitable solutions for companies of all sizes and allow for easy scaling in the future.
Learn latest trends in data engineering to maintain a competitive edge
Machine learning as a data pipeline automation solution
Wherever machine learning is used today, it is one of the most powerful and rapidly developing tools for working with data. Although it is rarely used as an independent tool, mixing it with other technologies, its importance is almost invaluable. Gartner predicts that 75% of organizations will deploy AI and ML technologies with data engineering. You may wonder: what can you do with machine learning in data engineering?
-
Predict and prevent pipeline failures or performance issues with ML models.
-
Detect and correct data anomalies, ensuring data quality automatically with ML algorithms.
-
Enhance ETL operations by automating data transformations based on learned patterns and behaviors.
TensorFlow Extended (TFX), Apache Spark MLlib or Kubeflow may help you to deploy, orchestrate, and manage ML workflows.
Open-source data engineering tools and frameworks
Open-source tools and frameworks are gaining popularity. A survey by Databricks indicates that 87% of data engineering teams utilize these open-source platforms, attracted by their cost-effectiveness and flexibility. By the way, about possibilities and flexibility. Here is just a short list of what you get with open-source tools:
Ability to modify and extend tools to meet specific requirements;
Access to a large developer community to collaborate and solve problems;
Reducing the cost of software licensing, because they are available for free;
Open codebases provide transparency and build trust.
To build a proper data engineering road map you can use Apache Kafka or Airflow, dbt (Data Build Tool) or Flink.
Continuous learning and adaptation are key to thriving in the dynamic landscape of data engineering. You should be well-equipped to meet the challenges and opportunities of the future.
Summing up
You might notice that the best practices and strategies mentioned in this article meet major pain points in data engineering workflows. Here is another tip to optimize your workflows, by solving key issues, you also get better results. Although we would like you to use all the tips in this article, we objectively understand that this is impossible. On the contrary, it can be ineffective. Before implementing the latest technologies, agile methodologies, or new tools to create a new data engineering roadmap, analyze and audit your current processes. This will help you choose the best strategy.
You can combine and mix them to integrate into your current data management system. Whether you choose automation and modular design, pay more attention to security and data protection, or work to improve collaboration within your team, don't forget that constantly updating your methods is the best way to go. Already have something in mind? Feel free to contact our manager and discuss your needs and expectations, we might have a solid solution for you.
Make your data reliable now