You’ve probably heard of the Okta breach. Well, it could be water under the bridge but remains hazardous though. Efficiency and reliability have become paramount. Businesses today rely on software solutions to deliver value to customers, and any downtime or performance issues can have significant consequences. You can’t be safe and sound even with the cutting-edge security technologies, hand down. But they may become your rescuer in some cases. This is where methodologies like Site Reliability Engineering (SRE) and DevOps step into the spotlight, revolutionizing the way we optimize software operations and boost reliability.
Site Reliability Engineering: It is a concept pioneered by Google and has gained widespread recognition for its ability to enhance system reliability and performance. By applying engineering principles to operations work, SRE emphasizes automation, monitoring, and the balance between reliability and development velocity.
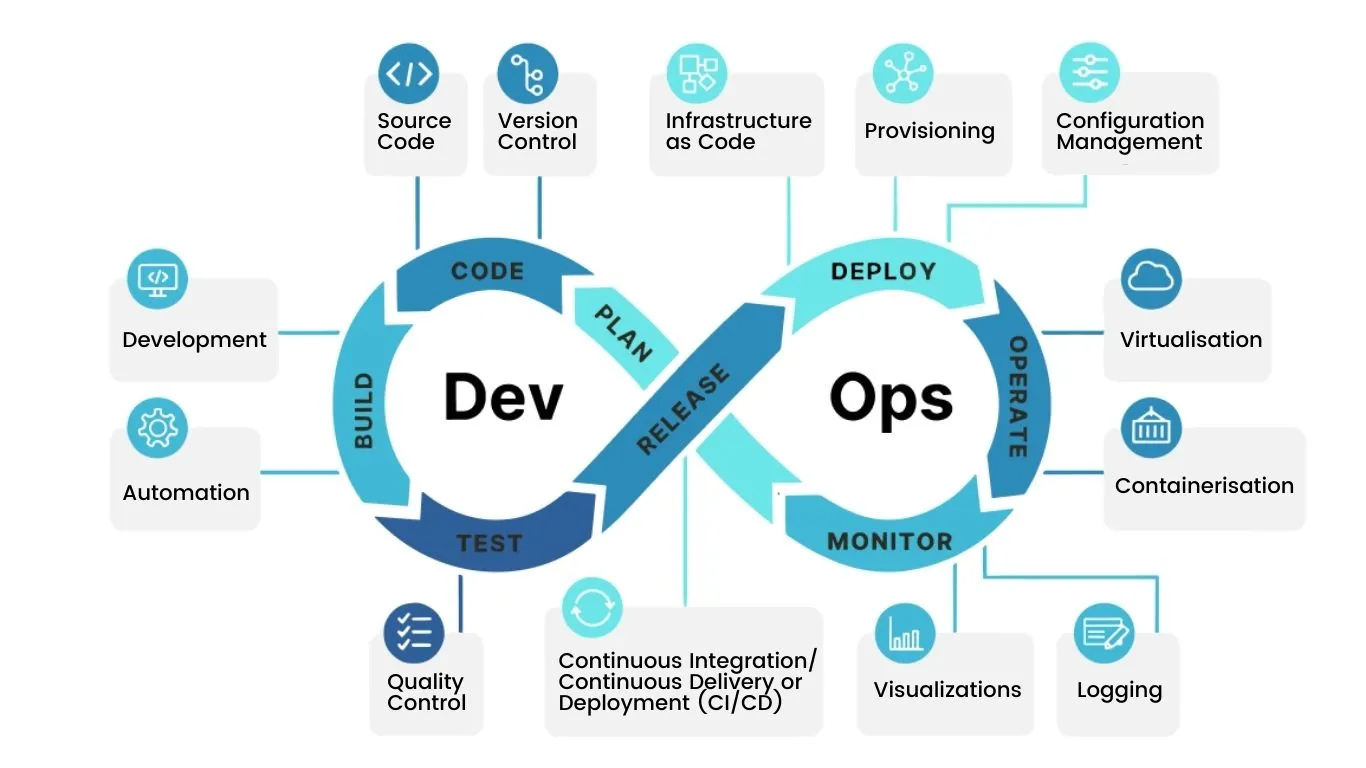
DevOps Methodology: It is a collaborative approach that bridges the gap between development and operations teams. It promotes a culture of shared responsibility, where developers and IT operations work together throughout the software development lifecycle. DevOps has been the driving force behind rapid software delivery, reducing time-to-market, and ensuring code quality.
As we already said, Google has been a pioneer in SRE, and its team has played a key role in the success of many of its products and services, such as Gmail, Search, and YouTube. For example, Google's SRE team has helped to reduce the number of outages for Gmail by 99.9%.
The Main Battle: SRE vs. DevOps
To truly grasp the differences between SRE and DevOps, it's essential to start by defining these two methodologies.
Site Reliability Engineering (SRE)
Google is a well-known giant that has a reputation for running some of the most reliable and high-traffic online services and is actually the father of SRE. At its core, SRE represents the marriage of software engineering and IT operations. It introduces engineering rigor and principles to the traditionally reactive world of operations, emphasizing proactive measures to ensure system reliability.
The Salt of SRE:
Measuring Reliability: SRE is built on a foundation of quantifiable reliability objectives. It involves setting Service Level Objectives (SLOs) and Service Level Indicators (SLIs) to measure system performance. These metrics provide a clear understanding of how reliable a service is and guide improvements.
Ever-Automating: Automation is a key tenet of SRE. Imagine your Spotify account searching and adding music you like to the Favorite Playlist. It frees you from the search and solves your need for new quality music. Similarly, by automating repetitive tasks and implementing self-healing mechanisms, SRE teams aim to reduce manual intervention, mitigate human error, and maintain system stability.
Shared Ownership: The responsibility for the reliability of a service is shared between the development and operations teams. Just compare it to animals locked in cage. They need to cooperate to get let off. Likewise, shared ownership in SRE fosters collaboration and ensures that both groups work together to achieve the common goal of a reliable system.
Goal of SRE:
To balance system reliability and feature development. SRE teams must be proactive. They focus on identifying and mitigating potential issues, allowing development teams to continue innovating without compromising system stability. By defining clear SLOs and using automation to maintain these objectives, SRE enables organizations to offer reliable services even in complex, dynamic environments.
DevOps
DevOps, in opposite to SRE, is a cultural and operational philosophy that emphasizes collaboration between development and IT operations teams. It seeks to break down traditional silos, fostering an environment where these two groups work together throughout the software development lifecycle.
The Salt of DevOps:
Automation: DevOps relies heavily on automation, aiming to eliminate manual, error-prone processes. It’s all about automated testing, deployment, and infrastructure provisioning. This way, DevOps accelerates the software development and delivery pipeline.
Continuous Integration/Continuous Delivery (CI/CD): CI/CD is the basis, fundament, soil of DevOps. It basically means continuously integrating code changes, running automated tests, and delivering code to production rapidly and reliably. This ensures that new features and fixes reach users faster.
Rapid Iteration: This approach enables teams to respond quickly to changing requirements and user feedback, leading to a more agile and responsive development process.
Goal of DevOps:
What is the primary goal of DevOps? To achieve faster and more reliable software delivery rolled into one. It actually removes barriers between development and operations and promotes a streamlined, collaborative workflow. This way, the development cycles become shorter, deployment risks are reduced, and the ability to adapt to market changes swiftly increases.
Key Differences Between SRE and DevOps
As we delve deeper into the realm of Site Reliability Engineering (SRE) and DevOps, it becomes evident that while they share a common goal of enhancing software operations and reliability, they take distinct paths to achieve this. Let’s sort the wheat from the chaff.
1. Focus and Approach
SRE: Site Reliability Engineering primarily centers on ensuring system reliability and availability. Perfect system work is achievable by implementing engineering practices, setting clear reliability objectives, and maintaining a focus on minimizing outages and disruptions.
DevOps: This methodology prioritizes improving collaboration and communication between development and IT operations teams. It seeks to break down traditional gaps, promoting a cultural shift toward shared responsibility and collaborative problem-solving.
2. Metrics and Objectives
SRE: Metrics in the SRE world revolve around Service Level Indicators (SLIs), Service Level Objectives (SLOs), and Service Level Agreements (SLAs). These metrics provide a clear and quantifiable measure of system reliability, guiding the SRE team's efforts.
Service Level Indicators (SLIs): SLIs are quantitative measures of the performance of a system. For example, an SLI for a web application might be the percentage of requests that are served in less than 1 second.
Service Level Objectives (SLOs): SLOs are targets for SLIs. For example, an SLO for a web application might be that 99.9% of requests are served in less than 1 second.
Service Level Agreements (SLAs): SLAs are agreements with customers that define the level of service that they can expect. SLA for a web application might state that the application will be available 99.9% of the time.
DevOps: DevOps, in contrast, focuses on metrics related to the speed of delivery, frequency of releases, and mean time to recovery (MTTR). These metrics are more concerned with the efficiency of the software delivery pipeline and the team's ability to respond to and recover from incidents quickly.
Speed of delivery: The speed at which new features are released to customers.
Frequency of releases: The number of times software is released to production in a given period of time.
Mean time to recovery (MTTR): The average time it takes to recover from a failure.
3. Roles and Responsibilities
SRE: There's typically a dedicated SRE team responsible for site reliability, monitoring, and incident response. This team is tasked with proactively ensuring system reliability and availability.
DevOps: This approach is all about a culture of shared responsibility. It blurs the lines between development and operations. Developers take on more operations-related tasks, and operations staff gain a deeper understanding of the development process.
4. Automation and Tooling
SRE: Automation is a cornerstone of SRE. It places a heavy emphasis on automating tasks related to managing infrastructure, deployments, and scaling. This automation helps minimize human error and ensures that systems are highly resilient.
DevOps: While automation is crucial in DevOps, it primarily focuses on automation in software delivery processes, CI/CD pipelines, and environment provisioning. The goal is to streamline the development pipeline and ensure that code is deployed quickly and reliably.
5. Risk Management
SRE: SRE addresses risk management through the concept of error budgets. An error budget is the acceptable level of unreliability that a service can tolerate within a given timeframe. SRE teams work to stay within this budget to balance reliability and feature development.
DevOps: Risk management here revolves around minimizing risks by implementing automated testing, code reviews, and infrastructure as code practices. By catching issues early in the development process and having automated recovery procedures, DevOps seeks to reduce the potential impact of failures.
DevOps vs. SRE: Benefits and Challenges
In software operations, both Site Reliability Engineering (SRE) and DevOps offer a unique set of perks and challenges. Let's elaborate on what each methodology brings to the table, as well as the potential roadblocks organizations might encounter.
Benefits: Comparative Table
Benefit
Explanation
Benefit
Explanation
Improved system reliability and availability
SRE focuses on maintaining and improving system reliability, resulting in fewer outages and service disruptions.
Faster time to market for software releases
DevOps practices, such as CI/CD, enable rapid and reliable software releases, reducing time-to-market.
Clear metrics for tracking and managing reliability
Through the use of SLIs, SLOs, and SLAs, SRE provides precise and quantifiable measures for system performance and reliability.
Enhanced collaboration and communication between teams
DevOps encourages a culture of collaboration and shared responsibility, leading to improved communication between development and operations.
Focus on proactive problem-solving and scalability
SRE promotes proactive measures to prevent incidents, scale systems efficiently, and ensure seamless operations.
Greater agility and adaptability to changing requirements
DevOps's iterative and agile approach enables organizations to quickly adapt to evolving market demands and user needs.
Challenges: Comparative Table
Challenge
Explanation
Challenge
Explanation
Resource-intensive due to specialized SRE teams
Establishing dedicated SRE teams and maintaining them can be resource-intensive, both in terms of expertise and cost.
Cultural resistance to change and collaboration
Transitioning to a DevOps culture can face resistance, as it requires a significant shift in organizational mindset and practices.
May result in slower feature development
The emphasis on reliability may lead to a cautious approach to feature development, potentially slowing down the release of new functionalities.
Requires significant investment in automation and tooling
Building and maintaining automated pipelines, testing frameworks, and infrastructure as code requires a substantial investment in technology and expertise.
When to Choose SRE or DevOps
Surprize — there is no right answer. If you are on the fence about which methodology to adopt – Site Reliability Engineering or DevOps – consider the organization's objectives, existing infrastructure, and the nature of its software operations.
Factors Influencing the Choice
Criticality of Reliability: If system reliability and availability are paramount for your company, SRE is a natural choice. It offers the rigor and discipline needed to ensure continuous service.
Development Speed and Agility: When rapid development cycles and quick releases are crucial, DevOps excels. Smaller teams and startups, where flexibility and adaptability are vital, often find DevOps principles to be the perfect fit.
Existing Culture and Expertise: What is your company’s culture about? Consider its current state, consider the expertise of your teams. Typically, shifting to DevOps faces resistance in siloed environments, while SRE might be a more gradual and manageable shift.
Resource Availability: Imagine you are an explorer, and before the travel, you scrutinize the map and future route. Likewise, assess the resource capabilities of your company. SRE often requires dedicated, specialized teams, which can be resource-intensive. DevOps, in opposite, necessitates investment in automation and tooling.
SRE vs. DevOps: Scenarios Where Each is More Suitable
Critical Infrastructure: SRE is ideal for organizations providing services that are mission-critical, where even a short outage could have severe consequences.
Rapid Development Cycles: DevOps shines in environments where rapid development and frequent releases are the lifeblood of the business.
Large-Scale Applications: SRE is a natural choice for platforms serving millions of users, where system reliability is non-negotiable.
Smaller Teams: Smaller teams often find DevOps more adaptable and less resource-intensive, making it a practical choice.
To sum it up
SRE places a laser focus on reliability and availability, with clear metrics and automation at its core. DevOps, on the other hand, fosters collaboration, accelerates development cycles, and enhances communication between teams.
We just want to make a point that SRE and DevOps are not mutually exclusive. In fact, they can complement each other beautifully. Organizations can leverage elements of both methodologies to tailor their approach to specific needs. The choice between SRE and DevOps—or a blend of both—depends on factors unique to each organization, making it crucial to assess requirements and objectives carefully.